# Tabby心得
Table of Contents
Tabby环境配置
工具简介:Tabby 是一款用于分析 Java 项目的静态分析工具,旨在结合图数据库和静态程序分析技术完成常见漏洞的挖掘。安全研究员可以使用 Tabby 快速检索 Java 项目中可能存在的安全风险,也可以使用 Tabby 完成特定类、函数、调用关系等内容的快速定位。
tabyy 2.0 本地环境 JDK17
首先把以下三个文件下好
- tabby.jar https://github.com/wh1t3p1g/tabby
- tabby-vul-finder https://github.com/wh1t3p1g/tabby-vul-finder
- tabby-path-finder https://github.com/wh1t3p1g/tabby-path-finder
建好工作目录(从tabby-core里面复制必要目录):
$ tree.├── cases # 用于放置待分析的项目,可以是单个文件,也可以是目录│ └── commons-collections-3.2.1.jar├── config # 用于放置配置文件│ ├── db.properties # 配置数据库相关内容│ └── settings.properties # 配置待分析项目、污点分析等内容├── output # 用于放置生成后的csv文件│ └── dev├── rules # 规则文件夹│ ├── basicClasses.json│ ├── commonJars.json # 用于排除无需分析的三方jar│ ├── cyphers.yml # 用于 tabby-vul-finder 自动化检索│ ├── sinks.json # 用于配置 sink 函数│ ├── system.json # 用于配置专家规则│ └── tags.json # 用于配置source点识别├── temp # v2.0 版本开始将临时文件都生成到同级temp目录下├── run.bat├── tabby-vul-finder.jar # 用于导入和自动化查询的 jar└── tabby.jar # 核心jar,用于生成图数据@echo off
if "%1"=="build" ( java -Xmx16g -jar tabby.jar) else if "%1"=="load" ( java -jar tabby-vul-finder.jar --load %2) else if "%1"=="query" ( java -jar tabby-vul-finder.jar --query %2) else if "%1"=="pack" ( tar -czvf output.tar.gz .\output\*.csv) else ( echo Usage: %0 [build^|load^|query^|pack] [argument] echo build - Run tabby.jar with 16GB memory echo load - Load data using second argument echo query - Query data using second argument echo pack - Create tar.gz archive of CSV files)neo4j配置
下载好neo4j社区版(这里我不推荐下载desktop,插件会有问题)+ apoc插件
- apoc-core https://github.com/neo4j/apoc
- apoc-extended https://github.com/neo4j-contrib/neo4j-apoc-procedures
连同之前下好的tabby-path-finder一起放到neo4j的plugin目录里。

然后在conf目录下:

apoc.conf
apoc.import.file.enabled=trueapoc.import.file.use_neo4j_config=falseneo4j.conf 修改
# A comma separated list of procedures and user defined functions that are allowed# full access to the database through unsupported/insecure internal APIs.dbms.security.procedures.unrestricted=my.extensions.example,my.procedures.*,jwt.security.*,apoc.*,tabby.*
# A comma separated list of procedures to be loaded by default.# Leaving this unconfigured will load all procedures found.dbms.security.procedures.allowlist=apoc.*,tabby.*初始化数据库
CREATE CONSTRAINT c1 IF NOT EXISTS FOR (c:Class) REQUIRE c.ID IS UNIQUE;CREATE CONSTRAINT c2 IF NOT EXISTS FOR (c:Class) REQUIRE c.NAME IS UNIQUE;CREATE CONSTRAINT c3 IF NOT EXISTS FOR (m:Method) REQUIRE m.ID IS UNIQUE;CREATE CONSTRAINT c4 IF NOT EXISTS FOR (m:Method) REQUIRE m.SIGNATURE IS UNIQUE;CREATE INDEX index1 IF NOT EXISTS FOR (m:Method) ON (m.NAME);CREATE INDEX index2 IF NOT EXISTS FOR (m:Method) ON (m.CLASSNAME);CREATE INDEX index3 IF NOT EXISTS FOR (m:Method) ON (m.NAME, m.CLASSNAME);CREATE INDEX index4 IF NOT EXISTS FOR (m:Method) ON (m.NAME, m.NAME0);CREATE INDEX index5 IF NOT EXISTS FOR (m:Method) ON (m.SIGNATURE);CREATE INDEX index6 IF NOT EXISTS FOR (m:Method) ON (m.NAME0);CREATE INDEX index7 IF NOT EXISTS FOR (m:Method) ON (m.NAME0, m.CLASSNAME);:schema //查看表库:sysinfo //查看数据库信息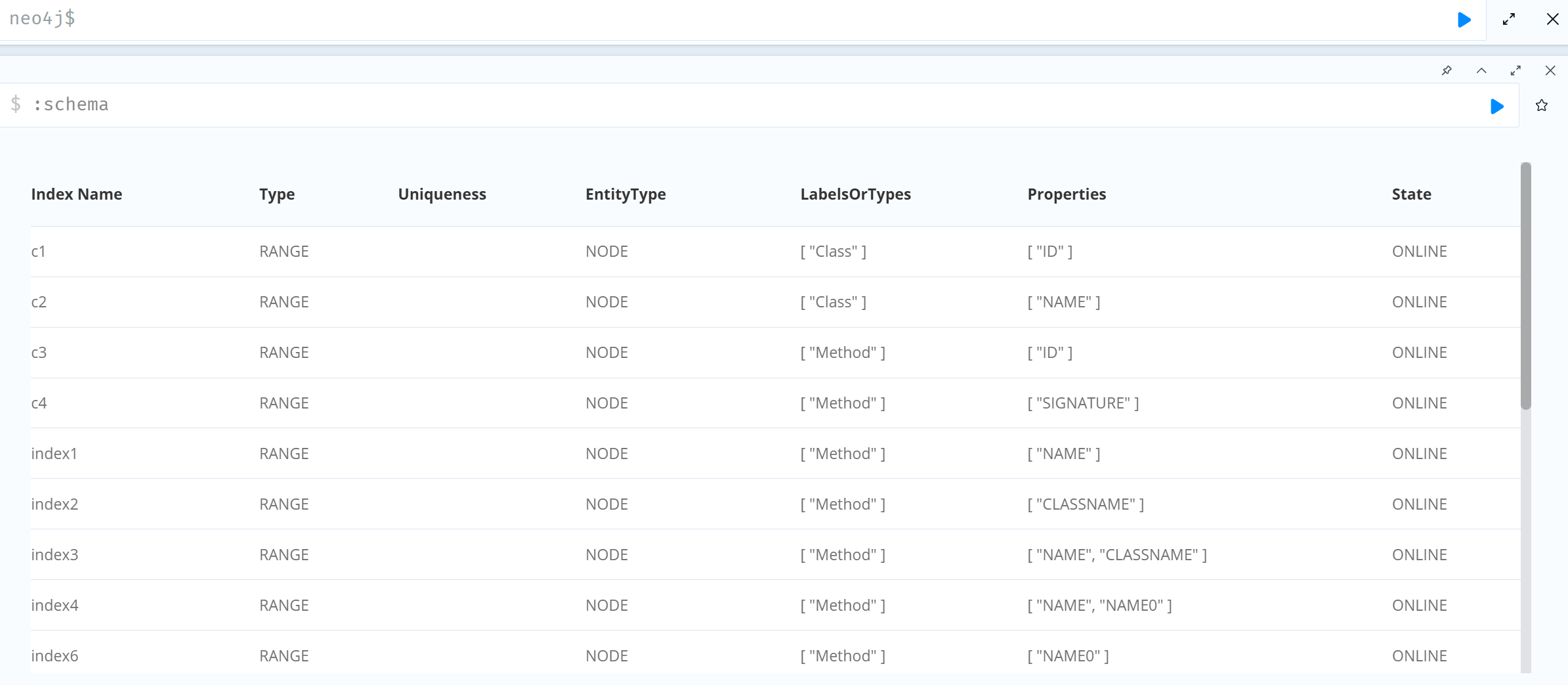
CALL apoc.help('all')CALL tabby.help('tabby')这两个命令不报错就是成功
IDEA插件
直接看文档 https://www.yuque.com/wh1t3p1g/tp0c1t/mxgt8v7yhguwmi0g
配置文件
具体根据不同场景修改请看原文:https://www.yuque.com/wh1t3p1g/tp0c1t/mgihyvp3vgscgt63
一些坑
-
如果你要自己编译vul-finder和path-finder的化可以用j11 + mvn3.9,实测不会报错。
-
neo4j企业版才能新建数据库,直接用默认的neo4j database就好了
-
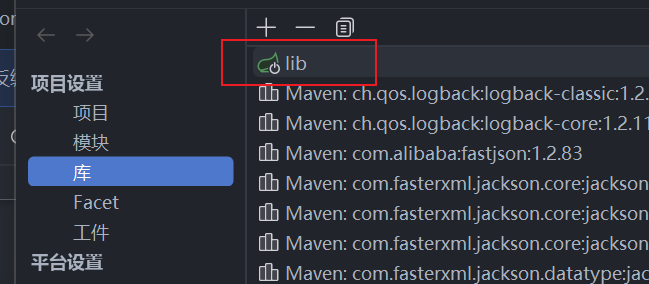
IDEA插件想要成功跳转要把lib添加到项目库里面
-
设置onlyJDK分析后下一次想要改版本需要把工作目录下的jre_libs删除
-
若要使用tabby-vul-finder记得把其仓库里面的rulescopy到自己本地的rules里面,正确语句
.\run.bat query .\rules\cc-cb.yml总体流程
先build出csv数据,然后load到你的neo4j数据库里面。接下来就开查。
Cypher & tabby-path-finder
Cypher 是 Neo4j 的声明式图查询语言。
其查询语句为返回子句
match (movie:Movie) where movie.rating > 7 return movie.title这也反映了其特征
(nodes)-[:CONNECT_TO]→(otherNodes)。圆括号用于圆形节点,-[:ARROWS]→ 用于关系。
基本概念例子
// 节点用圆括号表示(n) // 一个节点,变量名为n(person) // 一个节点,变量名为person(:Person) // 一个带标签Person的节点,没有变量名(p:Person) // 一个带标签Person的节点,变量名为p
// 关系用方括号表示,在两个节点之间-[r]-> // 有向关系,变量名为r-[:KNOWS]-> // 有向关系,类型为KNOWS-[k:KNOWS]-> // 有向关系,类型为KNOWS,变量名为k-[]- // 无向关系
// 基本匹配MATCH (n:Person) // 找所有Person标签的节点MATCH (p:Person {name: "Alice"}) // 找name属性为Alice的Person节点MATCH (p:Person)-[:KNOWS]->(f) // 找Person认识的所有人
//where 条件过滤MATCH (p:Person)WHERE p.age > 30 // 年龄大于30WHERE p.name =~ "A.*" // 名字以A开头(正则表达式)WHERE p.age IN [25, 30, 35] // 年龄在指定列表中
//with传递结果过MATCH (p:Person)WITH p, p.age * 2 AS doubleAge // 计算后传递给下一部分WHERE doubleAge > 60RETURN p.name
//collect聚合收集MATCH (p:Person)-[:KNOWS]->(f)WITH p, collect(f) AS friends // 将所有朋友收集到数组中RETURN p.name, friends
//call调用过程CALL db.labels() YIELD label // 调用系统过程RETURN label
// 调用自定义过程CALL my.procedure(param1, param2) YIELD resultRETURN result
//正则表达式WHERE p.name =~ ".*Smith" // 以Smith结尾WHERE p.email =~ ".*@gmail\\.com" // Gmail邮箱WHERE p.code =~ "org\\.apache\\..*" // 以org.apache.开头YIELD告诉Neo4j”我要从这个存储过程的返回结果中提取哪些字段”。
来分析一个tabby-path-finder的payload
match (source:Method {NAME:"toString"})where source.CLASSNAME=~"org.apache.commons.collections.*"
match (sink:Method {NAME:"get", CLASSNAME:"java.util.Map"})where sink.PARAMETER_SIZE=1
call tabby.algo.findJavaGadget(source, ">",sink, 5, false) yield path
// 黑名单//where none(n in nodes(path) where // n.CLASSNAME in [ // "java.io.ObjectInputStream", // "java.util.concurrent.ConcurrentHashMap" // ])
return path最常用的函数就是 tabby.algo.findJavaGadget 其他函数参考文章:https://www.yuque.com/wh1t3p1g/tp0c1t/ta9ldsycan538ndf
其签名:
source: 源节点
>:分析方向
sinks: 目标节点数组
5: maxNodeLength - 最大路径长度为5个节点
false: isDepthFirst - 使用广度优先搜索(而非深度优先)
那这个payload其实就是首先起始点为:cc依赖下的toString方法 然后再找Map接口的get方法作为sink点,然后过滤一下黑名单(如果有的话
这里我分析的jar是commons-collections-3.2.2.jar
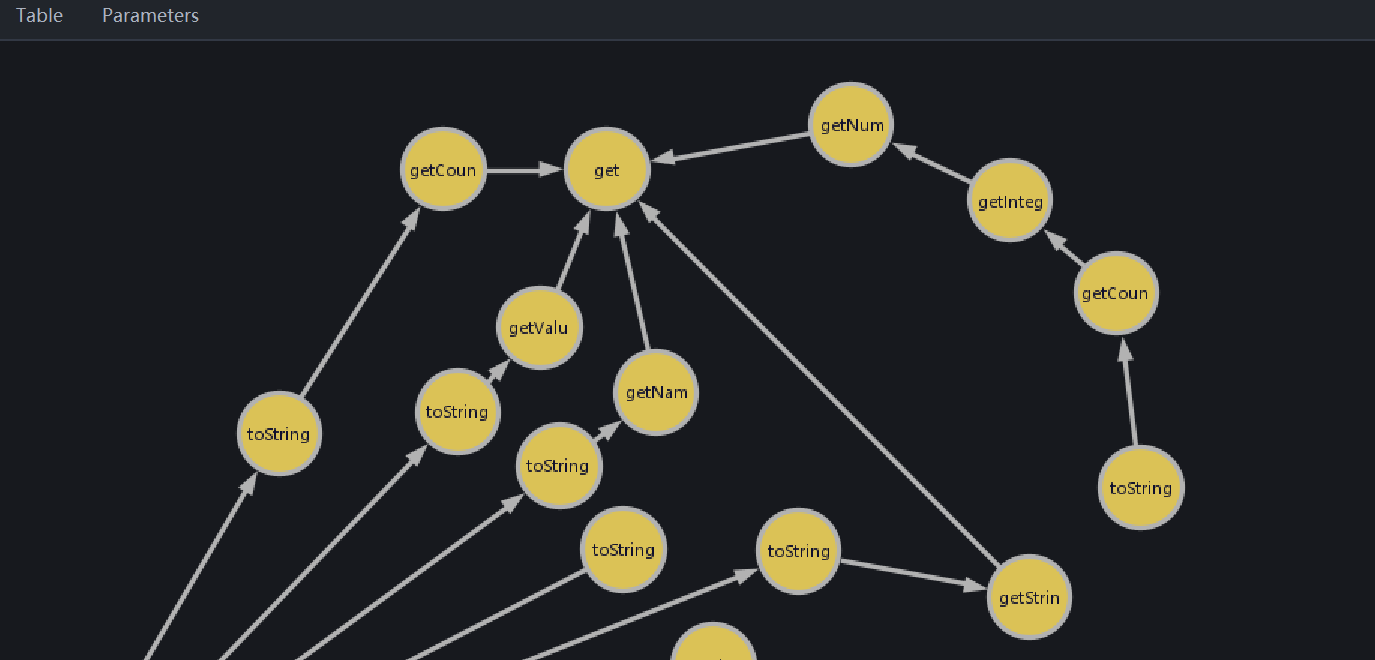
可以看到当长度调成4的时候,一共有5条链子
-
org.apache.commons.collections.DefaultMapBag#toString ->getCount ->getInteger->getNumber->map.get()
-
com.sun.xml.internal.ws.client.Stub#toString->getStringId-> this.getRequestContext().get(“javax.xml.ws.service.endpoint.address”);
-
sun.security.x509.AlgorithmId#toString->getName-> Map<ObjectIdentifier, String> nameTable.get()
-
org.apache.commons.collections.bag.AbstractMapBag#toString -> getCount -> map.get
-
org.apache.commons.collections.keyvalue.TiedMapEntry#toString -> getValue -> map.get
通过分析,链子2没有实现Serializable。其他都可以走。
如果长度设置为3就只有我们熟悉的TiedMap和AbstractMap了
